Capture The Flag Miscellaneous 5
Miscellaneous 【6】 🔒
Miscellaneous 【5】 –key{flag{misc}}
Miscellaneous 【4】 🔒
Miscellaneous 【3】
Miscellaneous 【2】
Miscellaneous 【1】
Ax Introduction
什么是CTF,什么是MISC。
CTF定义:网络安全技术人员之间进行技术竞技的一种比赛形式。CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们模拟攻击的比赛。
- 类型:解题模式、攻防模式、混合模式
- 赛事:DEFCONCTF、XCTF、Real World CTF等
- 题目:PPC、MISC、PWN、WEB、REVERSE、CRYPTO、STEGA
MISC定义:Miscellaneous,安全杂项,流量分析、电子签证、人肉搜索、数据分析等等等等等,就是除了最初的几个大类之外的题目。
别看杂项杂,每一项都是很专业的东西,所以要学的东西很多很多。还能遇到有些有趣的东西呢。
常见思路
压缩包:伪加密、爆破、找其它文件的解密密码
图片:
- jpg\png\bmp 隐写文件、LSB隐写、文件高度隐藏(图片残缺)
- gif 分裂拼接、分裂合成
多个文件:注意文件大小,压缩差,字节拼接
常用工具
WinHex yyds
010editor
kali linux
hexdump 二进制分析,二进制文件转换为ASCII、八进制、十进制、十六进制
pngcheck、tweakpng 查看png的CRC是否正确,错误则代表被修改宽高等
base64 转码
jadx-gui java反编译
binwalk 查看文件中是否隐藏信息
formost 通过分析文件头和内部数据结构和尾,还原文件,使文件分离出来。
zip2john 破解压缩包密码,再用
john看破解的密码文件zip2john flag.zip password.txt john password.txtfcrackzip zip压缩包破解工具
fcrackzip -b -c 'aA1!' -l 1-10 -u crack_this.zip # 选择大小写且数字!-b代表brute-force;-l限制密码长度;-c指定使用的字符集:-u是解压 fcrackzip -b -c '1' -l 1-10 -u crack_this.zip # 如果知道是数字,直接使用数字 gzip -d /usr/share/wordlists/rockyou.txt.gz # 解压kali自带的字典 fcrackzip -D -p /usr/share/wordlists/rockyou.txt -u crack_this.zip # 使用字典爆破crunch 密码字典生成
aircrack-ng wifi密码破解
tshark Linux版本的wireshark工具。
strings、egrep、awk 找东西滴
Wireshark 有时候会有分析数据包的取证题目需要用到。
隐写工具
- Jphs05 图片信息隐藏
- Stegsolve 分析图片隐写工具
- zsteg 隐写工具LSB
RouterPassview 路由器配置文件查看器
好玩的工具
- http://www.atoolbox.net/ 好好玩
- https://www.pdfpai.com/downgif2png
- https://www.11zon.com/zh-cn/
- https://the-x.cn/ 推荐
加密算法在线网站
- MD5
- 各种加密
Bx Flag{keyisflag}
只有不断的做题,才能学习到更多的东西,包括出题的套路,you know,but 作者的想法你是永远猜不到的,也许就在你意想不到的地方。
我会去做各大在线网站的题目,然后记录于此便于我回顾。
Bugku
Bugku_想要种子吗

得到一张jpg,首先随便简单看看,发现详细信息提示STEGHIDE,然后用这个工具打开,额,我没这个工具,Download一下。

简单滴学习了一下使用方法,得到一个文件,网盘地址?难道是,。种子?
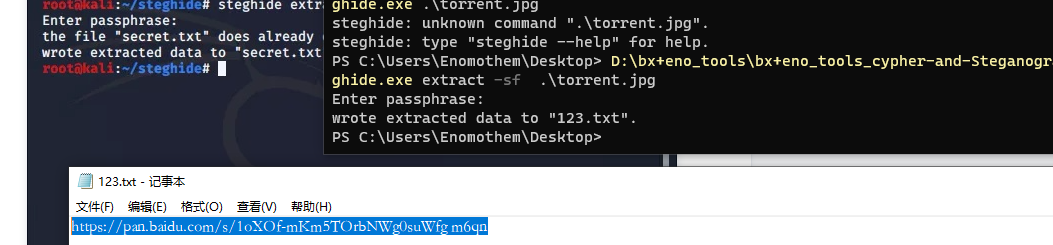
下载下来
解压需要密码,解压出一个txt里面的six six six不是密码,实在找不到密码了,直接爆破

牛逼。
还是啥都没,放binwalk看一下。
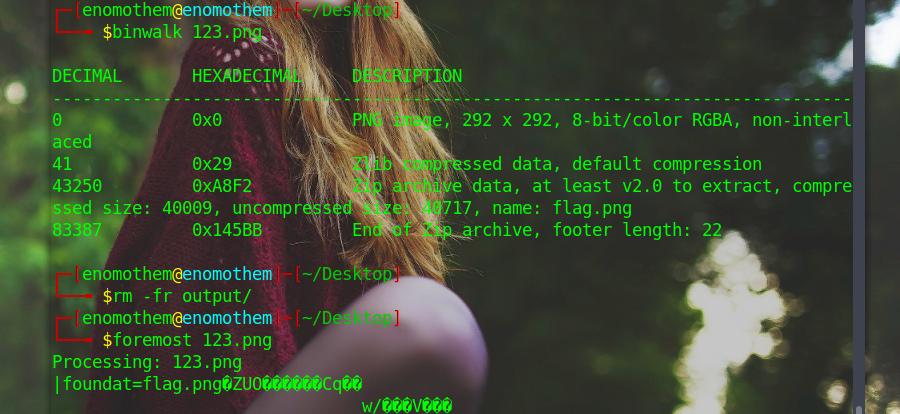
得到一张PNG,010打开报错,一般宽高出问题了,用脚本跑出宽高
import zlib
import struct
filename = 'flag.png'
with open(filename, 'rb') as f:
all_b = f.read()
crc32key = int(all_b[29:33].hex(),16)
data = bytearray(all_b[12:29])
n = 4095 #理论上0xffffffff,但考虑到屏幕实际/cpu,0x0fff就差不多了
for w in range(n): #高和宽一起爆破
width = bytearray(struct.pack('>i', w)) #q为8字节,i为4字节,h为2字节
for h in range(n):
height = bytearray(struct.pack('>i', h))
for x in range(4):
data[x+4] = width[x]
data[x+8] = height[x]
crc32result = zlib.crc32(data)
if crc32result == crc32key:
print("宽为:",end="")
print(width)
print("高为:",end="")
print(height)
exit(0)

修改后保存打开图片
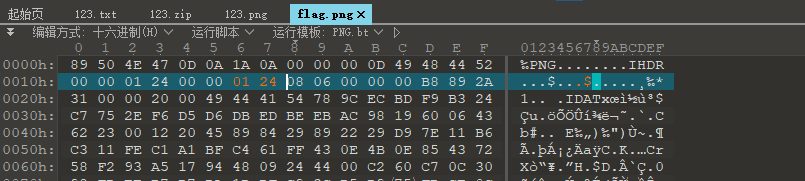
得到flag,不过是加密的

fkyg{SfirgsXmuqRoqpemr}
看看还有什么信息,底部得到一个网址,https://www.guballa.de/vigenere-solver,

是Vigenere Solver(维吉尼亚密码)选择English,得到flag。

flag{ThisisYourTorrent}
Bugku_blind_injection2
得到一个pcap包,这次有了上次的经验,尝试用命令搞定。
首先用tshark读取http请求的url,然后用正则取匹配和做一个去换行的工作。我不是大佬,所以就算用命令也得好几步,慢慢来。
# 读取;直接省略,匹配pcap文件。
# tshark -r time.pcap -T fields -e http.request.full_uri > time.txt
# 匹配
grep -o -P "=%20.{1,3}.," --text time.pcap
# 去杂
sed -i "s/=%20 //g" time.txt > time1.txt
# 转置
awk '{ORS = ""}{print $0} END {printf("\n")}' time1.txt
# 但我还是很不甘心啊!为什么我就不能一条命令呢,虽然我菜,命令可以笨一点嘛。经过我不懈努力下,得出三个awk的管道,哈哈
cat time.pcap | grep -Poa '=%20.{1,3}' | awk '{ sub(/=%20/,NULL); print $0 }' | awk '{ sub(/,/,NULL); print $0 }' | awk '{ORS = ","}{print $0} END {printf("\n")}'
没办法,菜啊

然后用脚本跑一下,将十六进制转为ASCII。
str = [往这里面丢]
for i in str:
print(chr(i), end='')

嫌麻烦直接丢在线
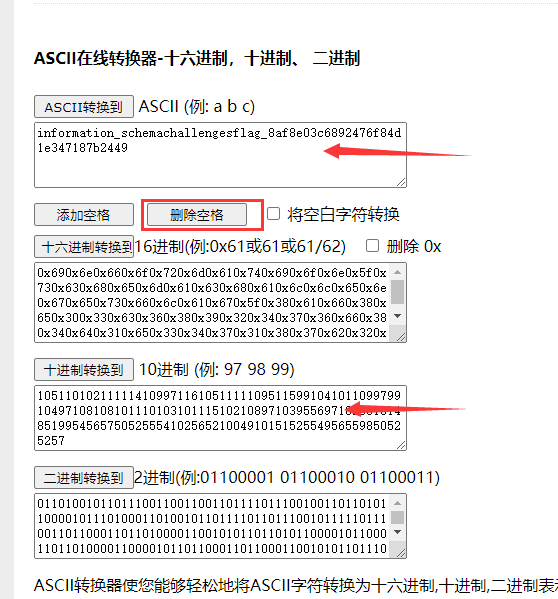
flag{8af8e03c6892476f84d1e347187b2449}
Bugku_where is flag
解压出10个文本,但是没有内容,题目提示 每个文件都不太一样呢,里面没有内容但字节数不同,工具字节数提取出来ASCII转字符。
工具有python和linux命令两种选择,当然还有人工一个一个弄出来。
用linux命令,记得把第一个放最后面去
wc -c *.txt | awk '{print $1}' | awk '{ORS = ""}{print $0} END {printf("\n")}'

98117103107117123110974810048110103100971079739305949125
# 这是用python方法
for n in range(1,11):
name = str(n)+'.txt'
with open(name) as f: # 文件的读取操作
print(len(f.read()),end=" ") # 显示文件长度
print("\n") # 显示看到文件长度文本1是98117,ascii就是bu,所以需自己分割,后面文本有点混了
# 最后处理转码
flag = '98 117 103 107 117 123 110 97 48 100 48 110 103 100 97 107 97 49 125'
flag = flag.split(' ')
for i in flag:
print(chr(int(i)),end="") # 转换成ascii码
bugku{na0d0ngdaka1}
Bugku_Pokergame
解压题目得到,hint里面是:@ 和 a 不要看混了,flag错了多试几遍flag{}

隐写工具没发现什么,图片送到LInux走一下,分别从这两种帕克中分离出半张二维码和一个压缩包。

分析这个压缩包
伪加密特征:
压缩源文件数据区的全局方式位标记应当为 00 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为 09 00 (50 4B 01 02 14 00 后)

将09修改为00解除加密。解压得到一个图片的Base64,老熟人了,方法也多,这次就直接往地址栏拖一下,应该是另一半的二维码
果不其然

画图打开,给它造在一起去,简直不要太完美。不过还缺了几个定位角,复制粘贴就行。
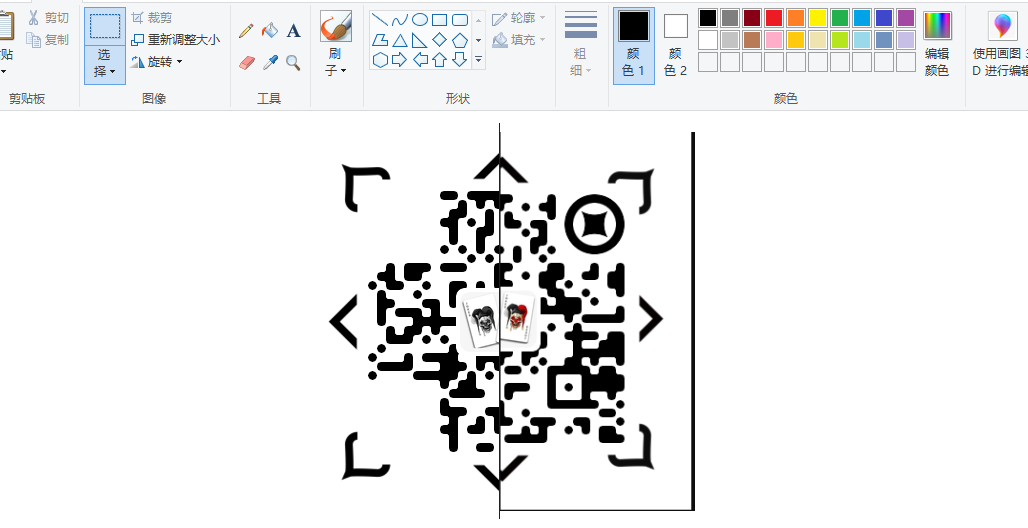
额。。扫不出来,再微调一下,左边可能有点长了点,再缩小一下

????,啥意思,看不起我,老子不用你了,换一家。
不错不错,下次还找你

回到最开始的那个压缩包,用这个key解开得到一些扑克牌
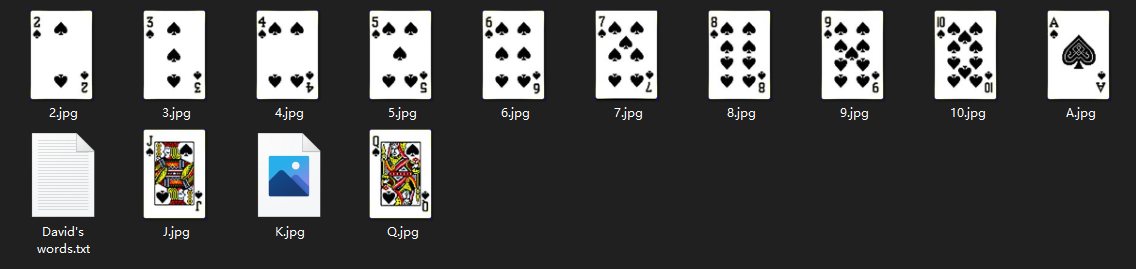
用010发现K.jpg是一个压缩包,需要密码,先看看别的。

David文本里面有一串数字,说只有A是1,想到这是二进制,除了1其它都是0,然后转成ASCII字符
cat tempsz.txt | awk '{gsub(/[0-9]/,"0") ; print $0 }' | awk '{ gsub(/A/,"1") ; print $0 }'
但是一直到无法解码,得到的是一个报错的码,我检查了之前的脚本发现零太多,这根本不可能是字符的二进制,除了A是1,其它的都是0,我发现了一个规律,那就是2345678910是一个固定的字符串,这串数据除了A就是’2345678910’,我们只需要把字符串转为0,而不是每个字符都转为0,这显然是不合理的,所以这是问题的关键点。
改进后的shell
cat tempsz.txt | awk '{gsub(/2345678910/,"0") ; print $0 }' | awk '{ gsub(/A/,"1") ; print $0 }'

显然,这样才合理
但是现在的问题是如何将二进制转为ASCII,方法有很多,但我想一步登天,你知道什么意思吧,就是比如说有这样的命令
# 这样
$ bin2ascii -a "Hello, world!"
1001000011001010110110001101100011011110010110000100000011101110110111101110010011011000110010000100001
# 这样
$ bin2ascii -b 1001000011001010110110001101100011011110010110000100000011101110110111101110010011011000110010000100001
Hello, world!
为此,我收集了一些资料准备写一篇文章出在Linux系列中。
经过学习了使用各种方法来转换ASCII字符后,我决定使用Perl,这是一个很好的语言。这样我们就达到了一条命令解决。
cat tempsz.txt | awk '{gsub(/2345678910/,"0") ; print $0 }' | awk '{ gsub(/A/,"1") ; print $0 }' | perl -lpe '$_=pack"B*",$_'
解出来是base64,我们仍然可以继续改进shell,再进行base64转ASCII

改进后的bash shell,仅需要再继续| base64 -d,即可获得base64解码后的字符串。
cat tempsz.txt | awk '{gsub(/2345678910/,"0") ; print $0 }' | awk '{ gsub(/A/,"1") ; print $0 }' | perl -lpe '$_=pack"B*",$_' | base64 -d

写到这里,我感慨到,shell真是好啊,我一定要写一个shell的笔记,因为我迫不及待的想要把shell的知识安利给你们,一起来学shell吧。

好了,回到题目中来,积累知识,沉淀知识,运用知识,分享知识,学而思,思而学。
得到key后,解压k.jpg.zip,得到以下内容。

翻转滴flag,啥意思,颜色反转?
还是老思路,管他三七二十一,往010一丢,难道winhex不配吗,哈哈,知道010之后确实更好用了。
想了一下,残缺的图片是否是修改了高度
这里学到一个好方法:将图片的宽高转为十六进制,然后去010里搜索,更方便定位
宽高为730×550 ,16进制 2DA 226,很快就定位到了 02 26 02 DA
想要看到另一头,至少高度要X3,把高度改为06 40
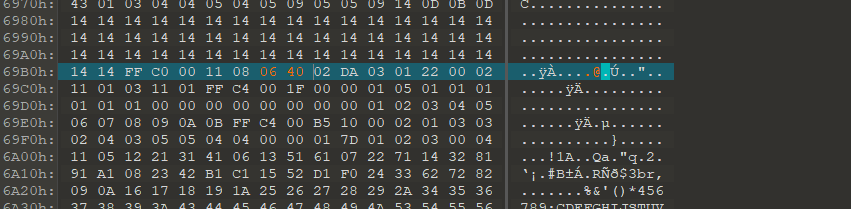
但是下面部分看不清除了

这里想到的是LSB隐写,用stegsolve打开。
得到隐藏的数据
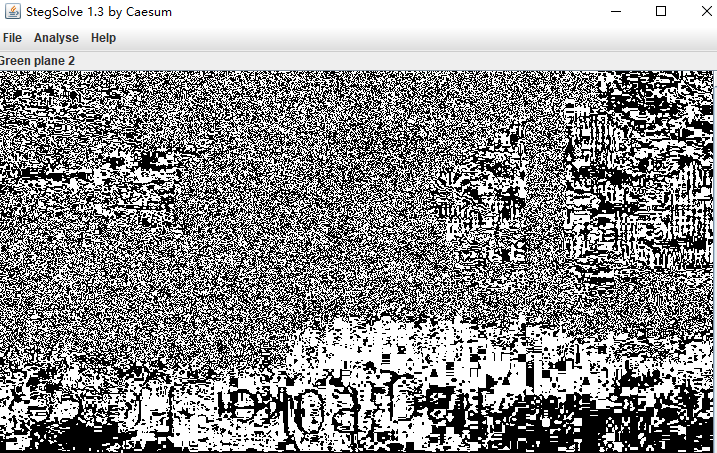
这谁看得清啊,旋转一下

通过识别的字样来看,可以猜到是题目名的变种flag{P0ker_F?ce},,不对,题目提示说@和a不要弄混了,?处应该是a但是应该是@
最后把0改o成功,好离谱,这明明是0。
Bugku_where is flag 4
下载得到一个文本,里面是Base64,解码发现是乱码,猜想是不是一个文件的二进制文件,转为十六进制。
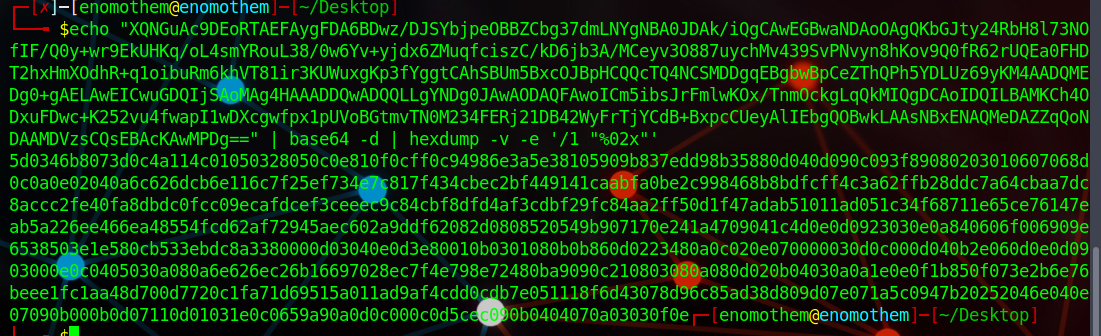
发现头部文件是ZIP的,但数据之间被插入无用字符,所以要提取奇数出来。
用python
src='5D0346B8073D0C4A114C01050328050C0E810F0CFF0C94986E3A5E38105909B837EDD98B35880D040D090C093F89080203010607068D0C0A0E02040A6C626DCB6E116C7F25EF734E7C817F434CBEC2BF449141CAABFA0BE2C998468B8BDFCFF4C3A62FFB28DDC7A64CBAA7DC8ACCC2FE40FA8DBDC0FCC09ECAFDCEF3CEEEC9C84CBF8DFD4AF3CDBF29FC84AA2FF50D1F47ADAB51011AD051C34F68711E65CE76147EAB5A226EE466EA48554FCD62AF72945AEC602A9DDF62082D0808520549B907170E241A4709041C4D0E0D0923030E0A840606F006909E6538503E1E580CB533EBDC8A3380000D03040E0D3E80010B0301080B0B860D0223480A0C020E070000030D0C000D040B2E060D0E0D0903000E0C0405030A080A6E626EC26B16697028EC7F4E798E72480BA9090C210803080A080D020B04030A0A1E0E0F1B850F073E2B6E76BEEE1FC1AA48D700D7720C1FA71D69515A011AD9AF4CDD0CDB7E051118F6D43078D96C85AD38D809D07E071A5C0947B20252046E040E07090B000B0D07110D01031E0C0659A90A0D0C000C0D5CEC090B0404070A03030F0E'
flag=''
for i in range(len(src)):
if i%2 == 0:
flag+=src[i]
flagzip=bytes.fromhex(flag)
with open('flag.zip','wb') as f:
f.write(flagzip)
得到一个压缩包,解压就可以获得flag
Bugku_清凉一夏
描 述: 二维码中藏着美女,想办法见到她,她会告诉你密码
得到:二维码
二维码得到:happyctf
显然不是扫码那么简单,将图片送检Linux。
在Linux一翻操作之后得到一个压缩包

得到:二维码+压缩包+图片
里面有一张gilr.jpg girl的英文都打错了。。打开需要密码,使用之前的在二维码扫描得到的key,得到图片文件,但打不开。
那肯定是文件头格式有问题,用010分析一下,头部信息缺失,将jpg头部FF D8 FF补上

图片恢复了

查看大小怀疑高度被修改,将高度调到
把高度修改得长一些,得到flag

key:U2FsdGVkX1+/JVhJjnTXAwi5whdn+NuW
这时候当然要去解密了,这是什么密码呢,查看密码特征发现是rabbit加密

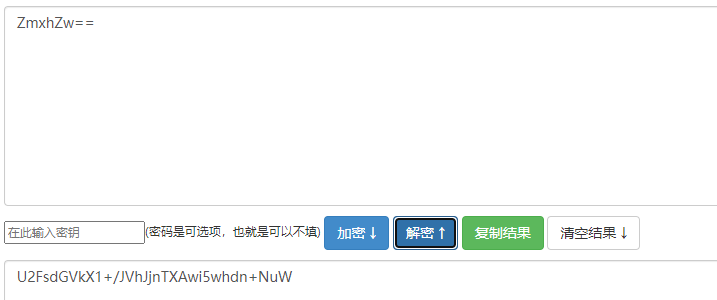
得到ZmxhZw==,是base64,直接解密,得到flag。

Bugku_做个游戏
描 述: 坚持60秒
发现坚持六十秒也是不行滴

直接使用jadx-gui反编译,搜索flag得到base64。

得到flag

Bugku_TLS
给了一个pcap包和一个server.key
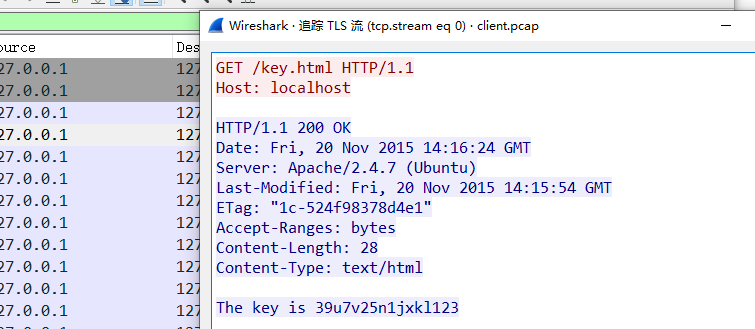
我也没有头绪,为此专门学习了一下TLS的协商和RSA算法。
server.key里面是一个rsa私钥,client包里面有TLS和TCP协商,追踪TLS流是空的。说明缺少私钥
将私钥导入到wireshark,重启wireshark追踪TLS流
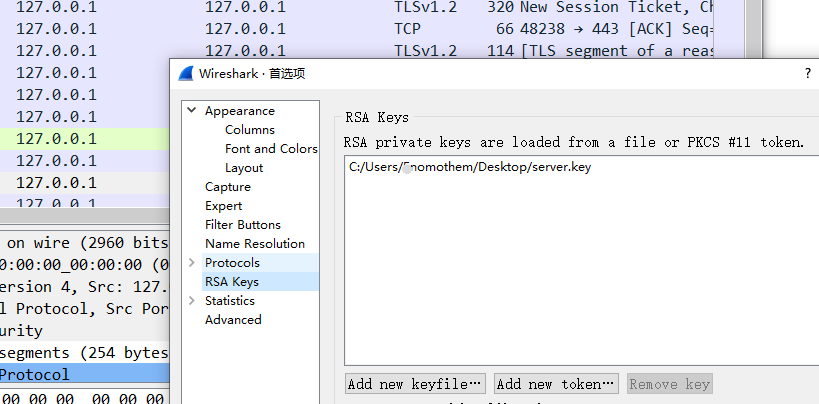
追踪到了流,出现一个key就是flag
flag{39u7v25n1jxkl123}
这题算是对我来说很偏的题,我不了解这方面的知识,但是很简单。
我找了相关的资料,有空做一个学习
扩展:
使用 RSA 768 位和 Wireshark 解密 HTTPS SSL/TLSv1
https://blog.stalkr.net/2010/03/codegate-decrypting-https-ssl-rsa-768.html
bsidessf-ctf-2017 root
https://www.jianshu.com/p/37d7be2c0172
https://www.jarvisoj.com/ ctf平台
https://github.com/Ganapati/RsaCtfTool RSA工具
Bugku_easy_python
这是游戏的代码
#coding=utf-8
import socket,threading
import math, base64
try:
level=open('.level').read()
level=int(level)
except:
level=1
class user():
HP=int(100+(4*level))
Danger=int(10+(3*level))
Defence=int(5+(1*level))
class npc():
name='穿山甲'
HP=(3**15)
Danger=(3**10)
Defence=100
print('面板\t血量\t攻击力\t防御力\t\n'),
print('玩家 %s\t%s\t%s\t\n'%(user.HP,user.Danger,user.Defence)),
print('怪物 %s\t%s\t%s\t\n'%(npc.HP,npc.Danger,npc.Defence)),
user.Danger=user.Danger-npc.Defence
npc.Danger=npc.Danger-user.Defence
if user.Danger <=0:
user.Danger=1
if npc.Danger <=0:
npc.Danger=1
print("开始战斗".center(41,'^'))
while 1:
npc.HP=npc.HP-user.Danger
print('你对%s造成了%s 怪物剩余血量 %s\t\n'%(npc.name,user.Danger,npc.HP))
user.HP=user.HP-npc.Danger
print('%s对你造成了%s 你剩余血量 %s\t\n'%(npc.name,npc.Danger,user.HP))
if npc.HP<=0 and user.HP<=0:
print('平局!!!')
break
if npc.HP <=0:
print('你赢了!!!,你剩余血量 %s\t\n'%(user.HP)),
break
if user.HP <=0:
print('你死了!!!%s剩余血量 %s\t\n'%(npc.name,npc.HP)),
break
print(("战斗结束 等级+1 您目前等级%s"%(int(level)+1)).center(49,'^'))
open('.level','w').write(str(level+1))
def battle(level)
HP = 4 level + 100
ATK = max(3 level - 90, 1)
M_ATK = max(3 10 - level - 5, 1)
return True if math.ceil(3 15 ATK) HP M_ATK else False
geitaoshenketou = 3 100 # 超大
l = [0, geitaoshenketou]
while True
if l[1] - l[0] == 1
res = base64.b64encode(str(l[1]).encode())
print('flag{' + res.decode() + '}')
break
elif battle(sum(l) 2)
l = [l[0], sum(l) 2]
else
l = [sum(l) 2, l[1]]
这题我不会做,花了点金币买了个WriteUp,更搞笑的是得到了代码还不会用,搜索报错发现就是语法错误,原来是我复制的时候有些符号缺失了,。。
WriteUp code
import math, base64
def battle(level):
HP = 4 * level + 100
ATK = max(3 * level - 90, 1)
M_ATK = max(3 ** 10 - level - 5, 1)
return True if math.ceil(3 ** 15 / ATK) < HP / M_ATK else False
geitaoshenketou = 3 ** 100 # 超大
l = [0, geitaoshenketou]
while True:
if l[1] - l[0] == 1:
res = base64.b64encode(str(l[1]).encode())
print('flag{' + res.decode() + '}')
break
elif battle(sum(l) // 2):
l = [l[0], sum(l) // 2]
else:
l = [sum(l) // 2, l[1]]
这题我算法不行,就不多说了。
Bugku_想蹭网先解开密码
得到一个cap包。
描 述: flag格式:flag{你破解的WiFi密码} tips:密码为手机号,为了不为难你,大佬特地让我悄悄地把前七位告诉你 1391040** Goodluck!! 作者@NewBee
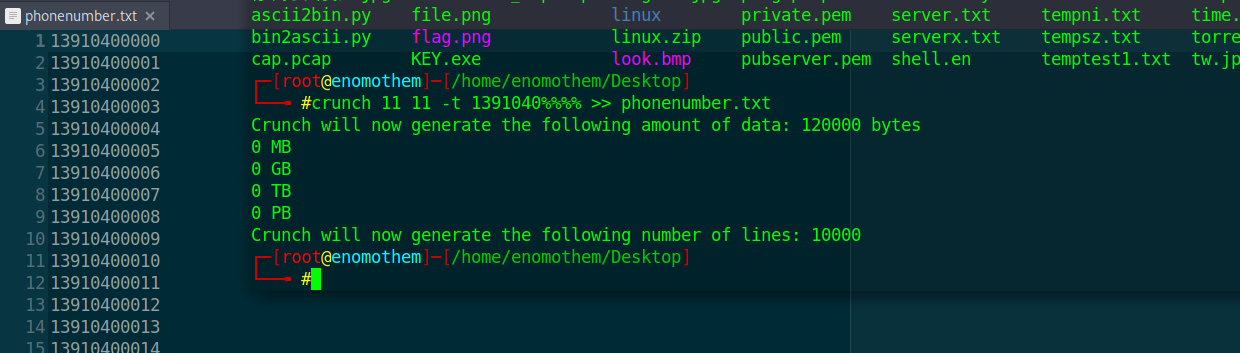
这个不就是生成社工字典,然后无线密码破解,直接打开工具吧,密码为手机号码,已经告诉了前七位,那么再遍历后四位
密码字典生成工具:那太多了,随便用什么工具,自己写python都可以,这里就用一个crunch命令行工具。
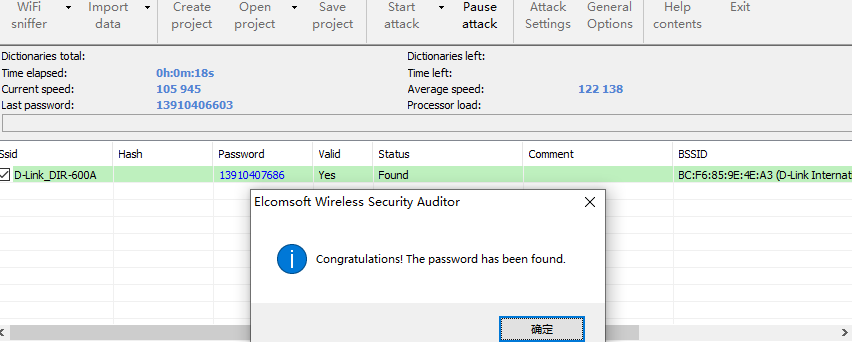
无线密码破解工具:Elcomsoft Wireless Security Auditor(GUI)、aircrack-ng(Linux)
生成社工字典
$ crunch 11 11 -t 13891040%%%% >> phonenumber.txt # -t 指定格式 >>也可以用-o代替
破解WIFI密码
$ aircrack-ng -w phonenumber.txt wifi.cap # 选3

再用个图形化工具试试
导入cap包,Import date > Import TCPDUMP File > 导入包
导入字典,Options>Dictionary Attack>导入字典
Start Attack,选择字典攻击。
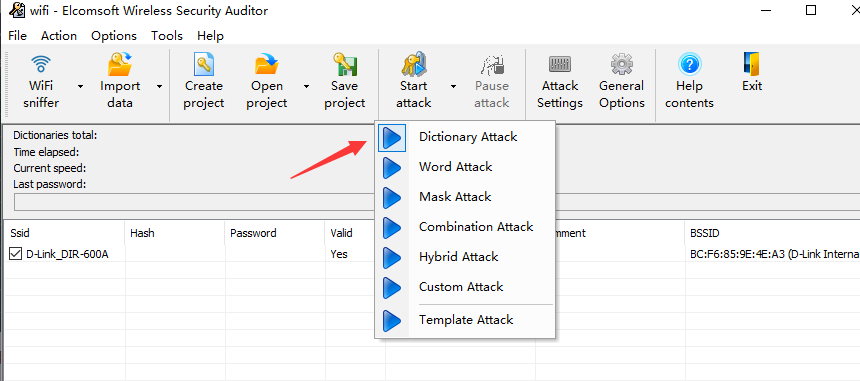
这个工具攻击有点慢,所以不推荐
Bugku_zip_伪加密
正如题目所提示,修改伪加密00 09为 00 00即可,解压得到flag

Bugku_三色绘恋
得到一张jpg,010看了一下发现存在不同的格式,binwalk分析,包含一个压缩包
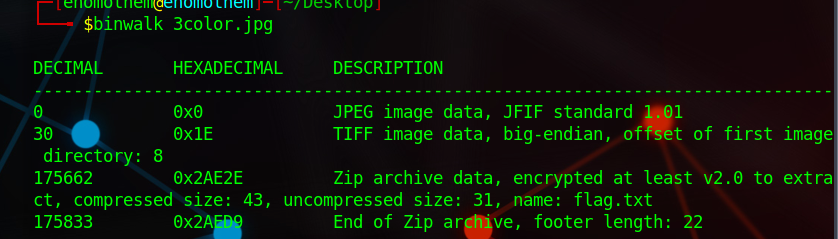
压缩包需要密码,突然看到图片出现了一串字符,而打开却没有,直接修改高度,得到flag

打开计算器计算一下,然后搜索定位,修改高度
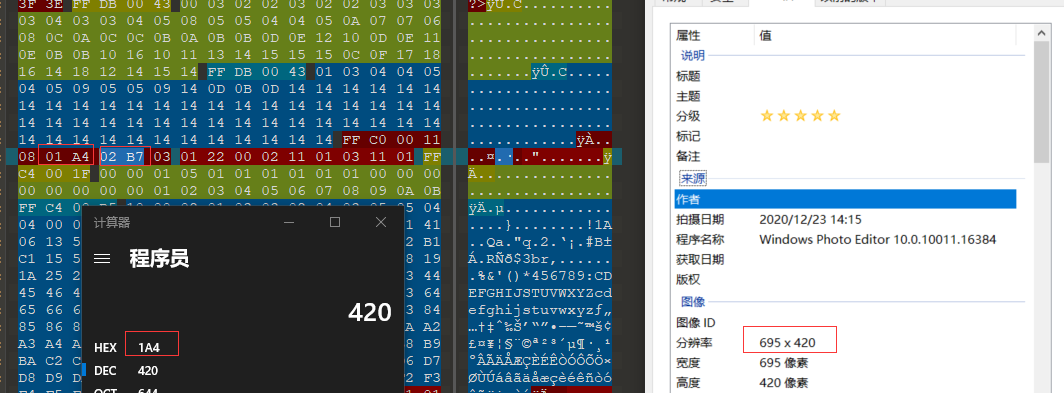
得到key

解压得到flag

Cx Additions
File Format
| 格式 | 头部 |
|---|---|
| .jpg | FF D8 FF |
| .png | 89 50 4E 47 |
| .bmp | 42 4D |
| .gif | 47 49 46 38 |
| .zip | 50 4B 03 04 |
| .rar | 52 61 72 21 |
| .avi | 41 56 49 20 |
25 50 44 46 |
常见格式
常用文件的文件头如下(16进制):
JPEG (jpg),文件头:FFD8FFE1
PNG (png),文件头:89504E47
GIF (gif),文件头:47494638
TIFF (tif),文件头:49492A00
Windows Bitmap (bmp),文件头:424DC001
CAD (dwg),文件头:41433130
Adobe Photoshop (psd),文件头:38425053
Rich Text Format (rtf),文件头:7B5C727466
XML (xml),文件头:3C3F786D6C
HTML (html),文件头:68746D6C3E
Email [thorough only] (eml),文件头:44656C69766572792D646174653A
Outlook Express (dbx),文件头:CFAD12FEC5FD746F
Outlook (pst),文件头:2142444E
MS Word/Excel (xls.or.doc),文件头:D0CF11E0
MS Access (mdb),文件头:5374616E64617264204A
WordPerfect (wpd),文件头:FF575043
Adobe Acrobat (pdf),文件头:255044462D312E
Quicken (qdf),文件头:AC9EBD8F
Windows Password (pwl),文件头:E3828596
ZIP Archive (zip),文件头:504B0304
RAR Archive (rar),文件头:52617221
Wave (wav),文件头:57415645
AVI (avi),文件头:41564920
Real Audio (ram),文件头:2E7261FD
Real Media (rm),文件头:2E524D46
MPEG (mpg),文件头:000001BA
MPEG (mpg),文件头:000001B3
Quicktime (mov),文件头:6D6F6F76
Windows Media (asf),文件头:3026B2758E66CF11
MIDI (mid),文件头:4D546864
图片格式
JPEG
JPEG格式说明
JPEG文件可以看作由多条数据段拼接成的文件,每条数据段包括两个部分:标记码和数据流。
标记码:由两个字节构成,其前一个字节为0xFF(通常只有一个0xFF,可以多个连续的0xFF),后一个字节则根据不同意义有不同数值。
数据流:记录了关于JPEG文件的相应信息(有些数据段无数据流)。
常用的数据段有SOI、APPx、DQT、SOF0、DHT、DRI、SOS、EOI等(SOI等只是数据段名,例如SOI是标记码为0xFFD8的数据段名,DHT是标记码为0xFFC4的数据段名)。
JPEG主要数据段说明
SOI ->Start of Image
含义:图像结束
标记码:0xFFD9 占2字节
数据流:无
APP0 ->Application 0(保留标记)
含义:应用程序保留标记0
标记码:0xFFE0——占2字节
数据流:
数据段长度——占2字节
标识符——5字节(固定值0x4A46494600=“JFIF0”)
版本号——2字节
密度单位——1字节(0->无单位 1->点数/英寸 2->点数/厘米)
X方向像素密度——2字节
Y方向像素密度——2字节
缩略图水平像素数目——1字节
缩略图垂直像素数目——1字节
缩略图RGB位图——长度为是3的倍数
APPx -> APPn->Application,x=1~15(可任选)
含义:应用程序保留标记x
标记码:0xFFE1~0xFFF——2字节(手机照片通常包含APP1,内容由地点,时间等)
数据流:
数据段长度——占2字节(不同数据段数据格式不同)
DQT ->Define Quantization Table,定义量化表
含义:定义量化表
标记码:0xFFDB——占2字节
数据流:
数据段长度——占2字节
量化表长度——占2字节
量化表ID——占1字节
量化表内容——占64字节
(量化表可以有多个,不超过4个)
SOF0 ->Start of Frame
含义:帧图像起始
标记码:0xFFC0——占2字节
数据流:
数据段长度——占2字节
精度——1字节
图像高度——2字节
图像宽度——2字节
颜色分量数——1字节(1-灰度图 3-YCrCb或YIQ 4-CMYK)
颜色分量信息——9字节
DHT ->Difine Huffman Table
含义:定义哈夫曼表
标记码:0xFFC4——占2字节
数据流:
数据段长度——占2字节
霍夫曼表长度——占2字节
表ID和表类型——1字节
不同位数的码字数量——16字节
编码内容——占16个不同位数的码字数量之和字节
DRI ->Define Restart Interval
含义:定义差分编码累计复位的间隔
标记码:0xFFDD——占2字节
数据流:
数据段长度——占2字节(长度固定为4)
MCU块的单元中的重新开始间隔——占2字节
SOS ->Start of Scan
含义:定义差分编码累计复位的间隔
标记码:0xFFC4——占2字节
数据流:
数据段长度——占2字节
颜色分量数——1字节(1-灰度图是 3-YCrCb或YIQ 4-CMYK)
颜色分量ID——1字节
直流/交流系数表号——1字节
压缩图像数据——3字节(固定值0x003F00)
EOI ->End of Image
含义:图像结束
标记码:0xFFD9 占2字节
数据流:无
PNG
PNG的文件头格式:
(固定)八个字节89 50 4E 47 0D 0A 1A 0A为png的文件头
(固定)四个字节00 00 00 0D(即为十进制的13)代表数据块的长度为13
(固定)四个字节49 48 44 52(即为ASCII码的IHDR)是文件头数据块的标示(IDCH)
(可变)13位数据块(IHDR)
前四个字节代表该图片的宽
后四个字节代表该图片的高
后五个字节依次为:
Bit depth、ColorType、Compression method、Filter method、Interlace method
压缩包格式
压缩源文件数据区:
50 4B 03 04是头文件的标志 (0x04034b50)00 00 全局方式标记(判断有无加密的重要标志)
压缩文件目录区
50 4B 01 02目录中文件头标志(0x02014b50)00 00 全局方式标记(有无加密的重要标志,更改这里就可以进行伪加密了,改为 09 00 打开就会提示有密码了。)
压缩源文件目录结束标志
50 4B 05 06目录结束标记
辨别真假加密:
无加密:
压缩源文件数据区的全局方式位标记应当为00 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为00 00 (50 4B 01 02 14 00 后)
假加密
压缩源文件数据区的全局方式位标记应当为 00 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为 09 00 (50 4B 01 02 14 00 后)
真加密
压缩源文件数据区的全局方式位标记应当为09 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为09 00 (50 4B 01 02 14 00 后)
Cypher Method
参考:L
Web类编码
# HTML源码
<a href="javascript:alert(1)">test</a>
# JS编码:
<a href="javascript:\u0061\u006c\u0065\u0072\u0074(1)">test</a>
# URL编码:
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(1)">test</a>
# HTML编码:
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(1)">test</a>
URL编码
一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。这意味着,如果URL中有汉字和其他符号,就必须编码后使用。我们在进行 URL 请求时,浏览器会自动帮我们把部分符号转换成 % + 十六进制数字 的形式
http://127.0.0.1/flag.php?x=1{)wo我
转化为
http://127.0.0.1/flag.php?x=1{)wo%E6%88%91
HTML实体编码
因为HTML对符号很敏感,比如空格,“<”,“>”等,于是这些符号需要用一些编码代替,这些编码就是HTML实体编码。
JavaScript编码
JavaScript编码主要是为了解决URL编码留下的坑进行的
escape()函数编码:形式为%uXXXX、%XX,字符范围0-F,本身就是URL编码的一种实现方式
Unicode 编码:'\u' + '四位十六进制数字'不够四位前面补0
JSFuck: 一种基于JavaScript原子部分的晦涩的编程风格,它只有6种字符:[ ] ( ) ! + ,也可以来编写程序并执行,可以做到所有JavaScript能做的事情
MD5
MD5以512位分组来处理输入文本,每一分组又划分为16个32位子分组。算法的输出由四个32位分组组成,将它们级联形成一个128位散列值。是不可逆的加密。
AES加密
特征:AES加密最重要的特征还是它的S-box,反汇编代码中很明显,而且容易定位
又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。
明文分组的长度为128位即16字节,密钥长度可以为16,24或者32字节(128,192,256位)。根据密钥的长度,算法被称为AES-128,AES-192或者AE-256。
从安全性来看,AES-256安全性最高 从性能来看,AES-128性能最高
sha1
对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。
CRS32
在诸多检错手段中,CRC是最著名的一种。CRC的全称是循环冗余校验。
特征:CRC32的计算结果只有8位
Cyclic Redundancy Check循环冗余检验,是基于数据计算一组效验码,用于核对数据传输过程中是否被更改或传输错误。 算法原理 假 设数据传输过程中需要发送15位的二进制信息g=101001110100001,这串二进制码可表示为代数多项式g(x) = x^14 + x^12 + x^9 + x^8 + x^7 + x^5 + 1,其中g中第k位的值,对应g(x)中x^k的系数。将g(x)乘以x^m,既将g后加m个0,然后除以m阶多项式h(x),得到的(m-1)阶余项 r(x)对应的二进制码r就是CRC编码。
h(x)可以自由选择或者使用国际通行标准,一般按照h(x)的阶数m,将CRC算法称为CRC-m,比如CRC-32、CRC-64等。国际通行标准可以look
g(x)和h(x)的除运算,可以通过g和h做xor(异或)运算。比如将11001与10101做xor运算:
这里把计算过程的要点记录一下:
CRC32是CRC算法一种,先参考Wiki上CRC算法的原理和实例搞明白基本的计算方法。
最常见的CRC32算法就是IEEE 802.3里生成FCS字段用的那个:
a) CRC32使用的Polynomial是 ,这个,图片缺失。。
b) IEEE 802.3在传送数据时使用的是最低有效位优先 (least significant bit first),所以要根据你机器的架构转换成有效的比特流输入。同理,输出流也一样。
c) 为了有效识别输入流开头和结尾的零,开头的32位要按位取反(complement),最后计算出的余数也要按位取反。
按照上述方法计算能得到想要的CRC32值了。
Base 系列编码
是我们最常见的编码,除此之外,其实还有 Base16、Base32、Base58、Base85、Base100 等,他们之间最明显的区别就是使用了不同数量的可打印字符对任意字节数据进行编码,比如 使用了 64 个可打印字符(A-Z、a-z、0-9、+、/),Base16 使用了 16 个可打印字符(A-F、0-9),这里主要讲怎么快速识别,其具体原理可自行百度,Base 系列主要特征如下:
- Base16:结尾没有等号,数字要多于字母;
- Base32:字母要多于数字,明文数量超过 10 个,结尾可能会有很多等号;
- Base58:结尾没有等号,字母要多于数字;
- :一般情况下结尾都会有 1 个或者 2 个等号,明文很少的时候可能没有;
- Base85:等号一般出现在字符串中间,含有一些奇怪的字符;
- Base100:密文由 Emoji 表情组成。
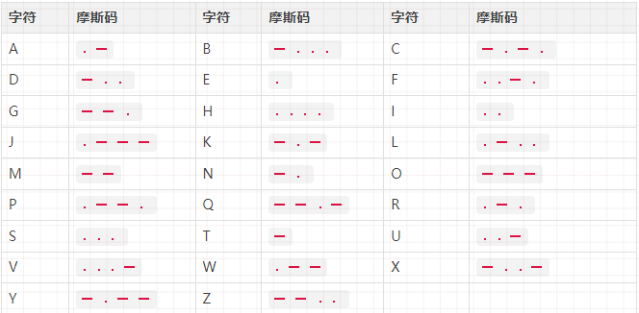
莫斯码


栅栏密码
特征:字母不会太多
①把将要传递的信息中的字母交替排成上下两行。
②再将下面一行字母排在上面一行的后边,从而形成一段密码。
明文:THE LONGEST DAY MUST HAVE AN END
加密:
1、把将要传递的信息中的字母交替排成上下两行。
T E O G S D Y U T A E N N
H L N E T A M S H V A E D
2、 密文:
将下面一行字母排在上面一行的后边。
TEOGSDYUTAENN HLNETAMSHVAED
解密:
先将密文分为两行
T E O G S D Y U T A E N N
H L N E T A M S H V A E D
再按上下上下的顺序组合成一句话
明文:THE LONGEST DAY MUST HAVE AN END
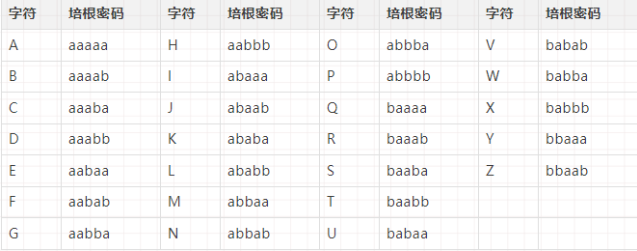
培根密码
培根密码,又名倍康尼密码(Bacon’s cipher)是由法兰西斯·培根发明的一种隐写术,它是一种本质上用二进制数设计的,没有用通常的0和1来表示,而是采用a和b,看到一串的a和b,并且五个一组,那么就是培根加密了。

凯撒密码
通过把字母移动一定的位数来实现加密和解密。明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。只需简单地统计字频就可以破译
维吉尼亚密码
维吉尼亚密码是在凯撒密码基础上产生的一种加密方法,它将凯撒密码的全部25种位移排序为一张表,与原字母序列共同组成26行及26列的字母表。另外,维吉尼亚密码必须有一个密钥,这个密钥由字母组成,最少一个,最多可与明文字母数量相等。维吉尼亚密码表如下:

猪圈密码
是一种以格子为基础的简单替代式密码,是共济会的暗号

波利比奥斯方阵
公元前2世纪,一个叫Polybius的希腊人设计了一种将字母编码成符号对的方法,他使用了一个称为Polybius的校验表,这个表中包含许多后来在加密系统中非常常见的成分。Polybius校验表由一个5行5列的网格组成,网格中包含26个英文字母,其中I和J在同一格中。相应字母用数对表示。在古代,这种棋盘密码被广泛使用。
rabbit加密
特征:有U2Fsd开头
utf-7编码
特征:url解码后可以看到如下,里面有“+/v++”,可以猜出这是UTF-7编码
UTF-7:这是一种使用7位ASCII码]对Unicode码进行转换的编码。它的设计目标仍然是为了在只能传递7为编码的邮件网关中传递信息。UTF-7对英语字母、数字和常见符号直接显示,而对其他符号用修正的Base64编码。符号+和-号控制编码过程的开始和暂停。所以乱码中如果夹有英文单词,并且相伴有+号和-号,这就有可能是UTF-7编码。
Uuencode编码
Uuencode是二进制信息和文字信息之间的转换编码,也就是机器和人眼识读的转换。Uuencode编码方案常见于电子邮件信息的传输,目前已被多用途互联网邮件扩展(MIME)大量取代。
Uuencode将输入文字以每三个字节为单位进行编码,如此重复进行。如果最后剩下的文字少于三个字节,不够的部份用零补齐。这三个字节共有24个Bit,以6-bit为单位分为4个群组,每个群组以十进制来表示所出现的数值只会落在0到63之间。将每个数加上32,所产生的结果刚好落在ASCII字符集中可打印字符(32-空白…95-底线)的范围之中。
Uuencode编码每60个将输出为独立的一行(相当于45个输入字节),每行的开头会加上长度字符,除了最后一行之外,长度字符都应该是“M”这个ASCII字符(77=32+45),最后一行的长度字符为32+剩下的字节数目这个ASCII字符。
rot13加密算法
Rot13是一种非常简单的替换加密算法,只能加密26个英语字母。方法是:把每个字母用其后第13个字母代替。
因为有26个字母,取其一半13。
s = "xrlvf23xfqwsxsqf"
ans = ""
for i in s:
if 'a' <= i <= 'z':
ans += chr(((ord(i)-ord('a')) + 13) % 26 + ord('a'))
else:
ans+=i
print(ans)
当铺密码
该加密算法是根据当前汉字有多少笔画出头,对应的明文就是数字几。
当前汉字有多少笔画出头,就是转化成数字几
例如:口 0 田 0 由 1 中 2 人 3 工 4 大 5 王 6 夫 7 井 8 羊 9
解密脚本
dh = '田口由中人工大土士王夫井羊壮'
ds = '00123455567899'
cip = '王壮 夫工 王中 王夫 由由井 井人 夫中 夫夫 井王 土土 夫由 土夫 井中 士夫 王工 王人 土由 由口夫'
s = ''
for i in cip:
if i in dh:
s += ds[dh.index(i)]
else:
s += ' '
#print(s)
ll = s.split(" ")
t = ''
for i in range(0,len(ll)):
t += chr(int(ll[i])+i+1)
print('t=', t, '\t\tt.lower()=', t.lower())
各种奇葩加密
与佛论禅/新约佛论禅
字符串转换后,是一些佛语。
与熊论道
字符串转换后,是一些熊语。
兽音译者
字符串转换后,是一些兽语。
社会核心价值观
字符串转换后,是社会核心价值观。
颜文字加密
字符串转换后,是颜文字。
Ook加密
https://www.splitbrain.org/services/ook
OOK!只有三个不同的语法元素:
Ook。
OOK?
OOK!



